|
I am a final-year PhD student at VILAB, EPFL, supervised by Amir Zamir. My research is broadly focused on developing deep learning systems that can perceive, understand, and act in the real world. Currently, I am working on learning multimodal representations that enable efficient world modeling and reasoning. For example, recently, I interned at Apple where we developed VideoFlexTok, an adaptive video tokenizer for efficient generative modeling. Previously I was a research intern at Apple, junior researcher at BayesGroup and Samsung-HSE Lab, supervised by Dmitry Vetrov. I got my BSc and MSc in Computer Science from the HSE University. 📧 Email / 📋 CV / 🎓 Google Scholar / 🧑💻 GitHub / 🐦 Twitter |

|
|
|
|
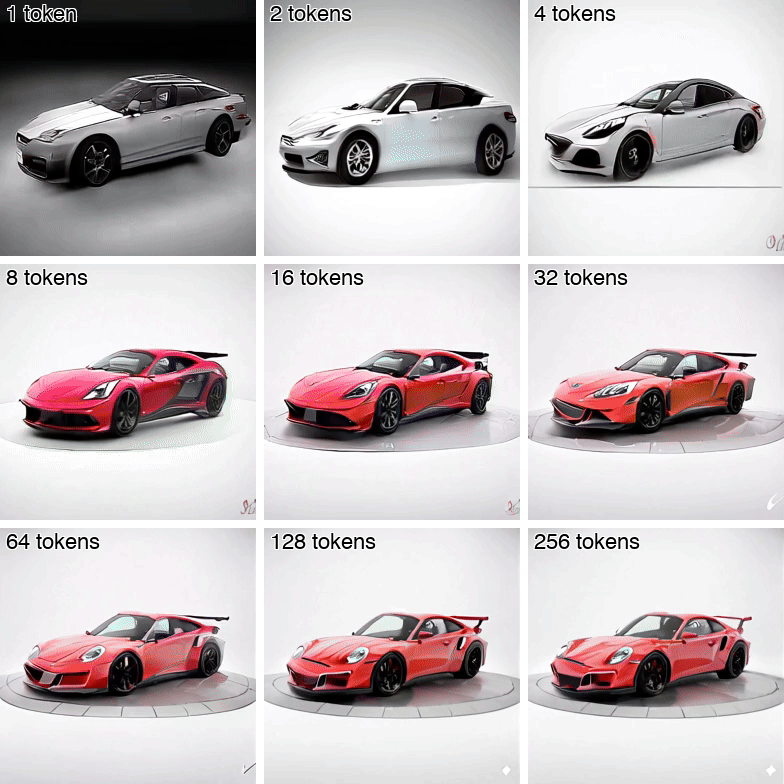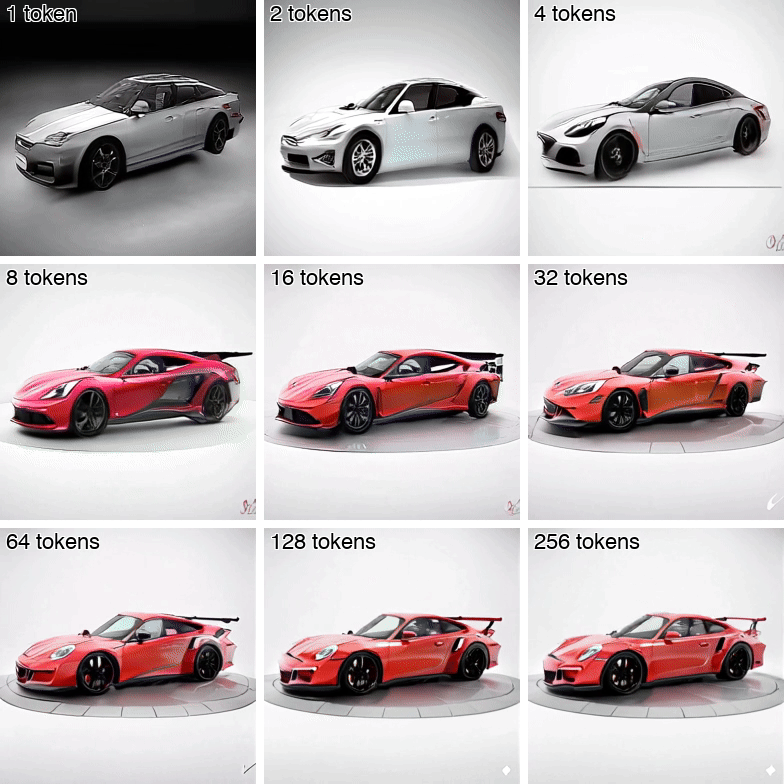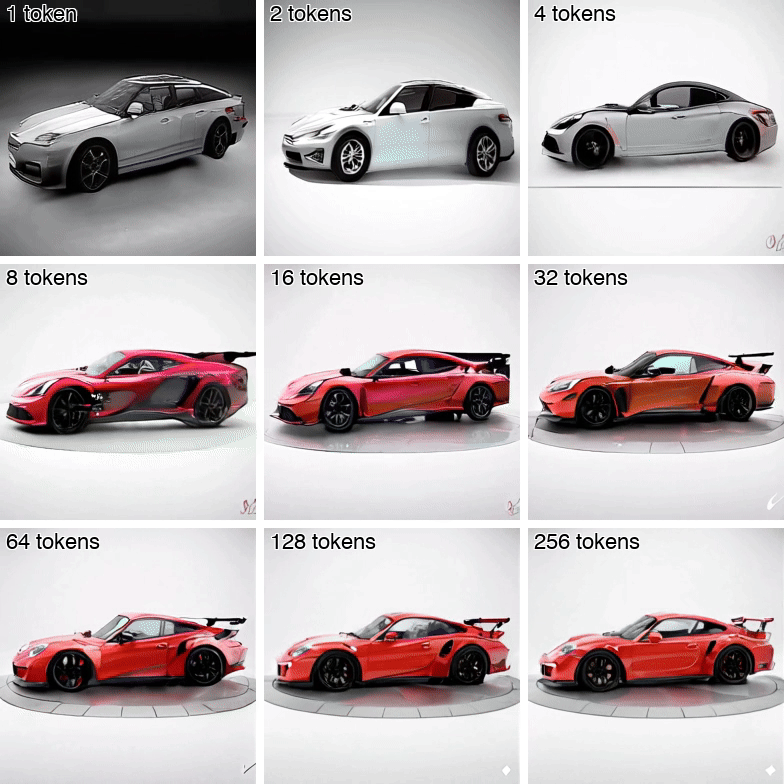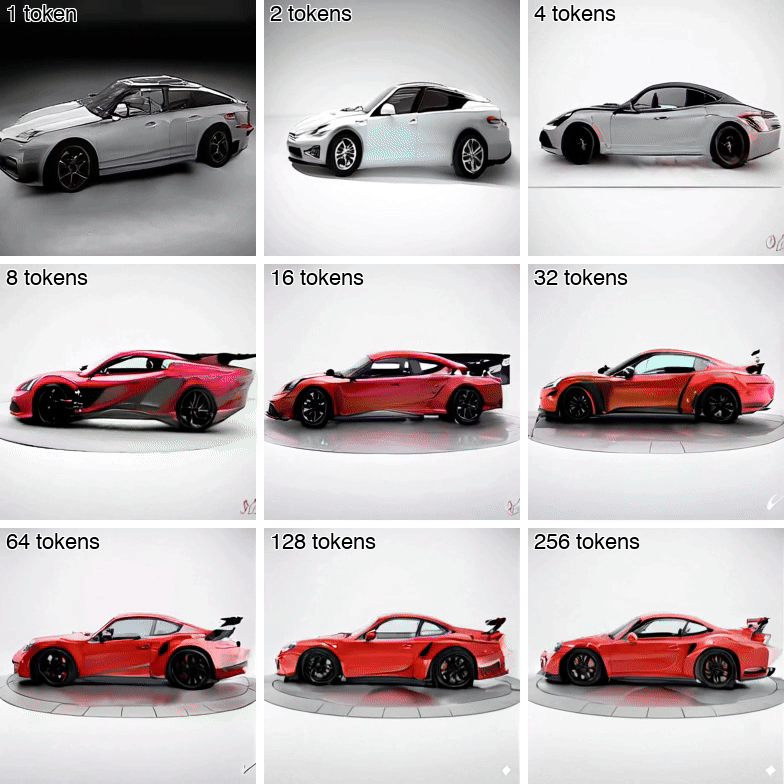
Andrei Atanov*, Jesse Allardice*, Roman Bachmann, Oğuzhan Fatih Kar, R Devon Hjelm, David Griffiths, Peter Fu, Afshin Dehghan, Amir Zamir ICML 2026 [Spotlight (top 2.2%)] [Project Page] [arXiv] [Demo] [GitHub] [X Thread] Isn't it wasteful to represent videos with full pixel-level detail? VideoFlexTok represents videos with a flexible-length coarse-to-fine sequence of tokens, where the first tokens capture abstract information (e.g., semantics and motion) and later tokens add finer details. See how the concept of a car and its motion are captured down to 1-4 tokens (first row). |

|
Kunal Pratap Singh*, Ali Garjani*, Rishubh Singh, Muhammad Uzair Khattak, Efe Tarhan, Jason Toskov, Andrei Atanov, Oğuzhan Fatih Kar, Amir Zamir ICLR, 2026 [Project Page] Do we need Internet-scale datasets to train vision models useful in a specific deployment environment? With Test-Space Training, we show that using only unlabeled multimodal data from the test environment, we can train specialist vision models that outperform generalist models trained on large-scale Internet data. |

|
Rahul Ramachandran, Ali Garjani, Roman Bachmann, Andrei Atanov*, Oğuzhan Fatih Kar*, Amir Zamir* ICLR, 2026 [Project Page] [arXiv] [GitHub] [X Thread] Different from language-focused evals, we evaluate popular multimodal foundation models (GPT-4o, Gemini, Claude, etc.) on standard computer vision tasks using established datasets (e.g., COCO, ImageNet). While these models demonstrate respectable generalist capabilities, we find that they lack behind specialist models, especially in geometric tasks. |
|
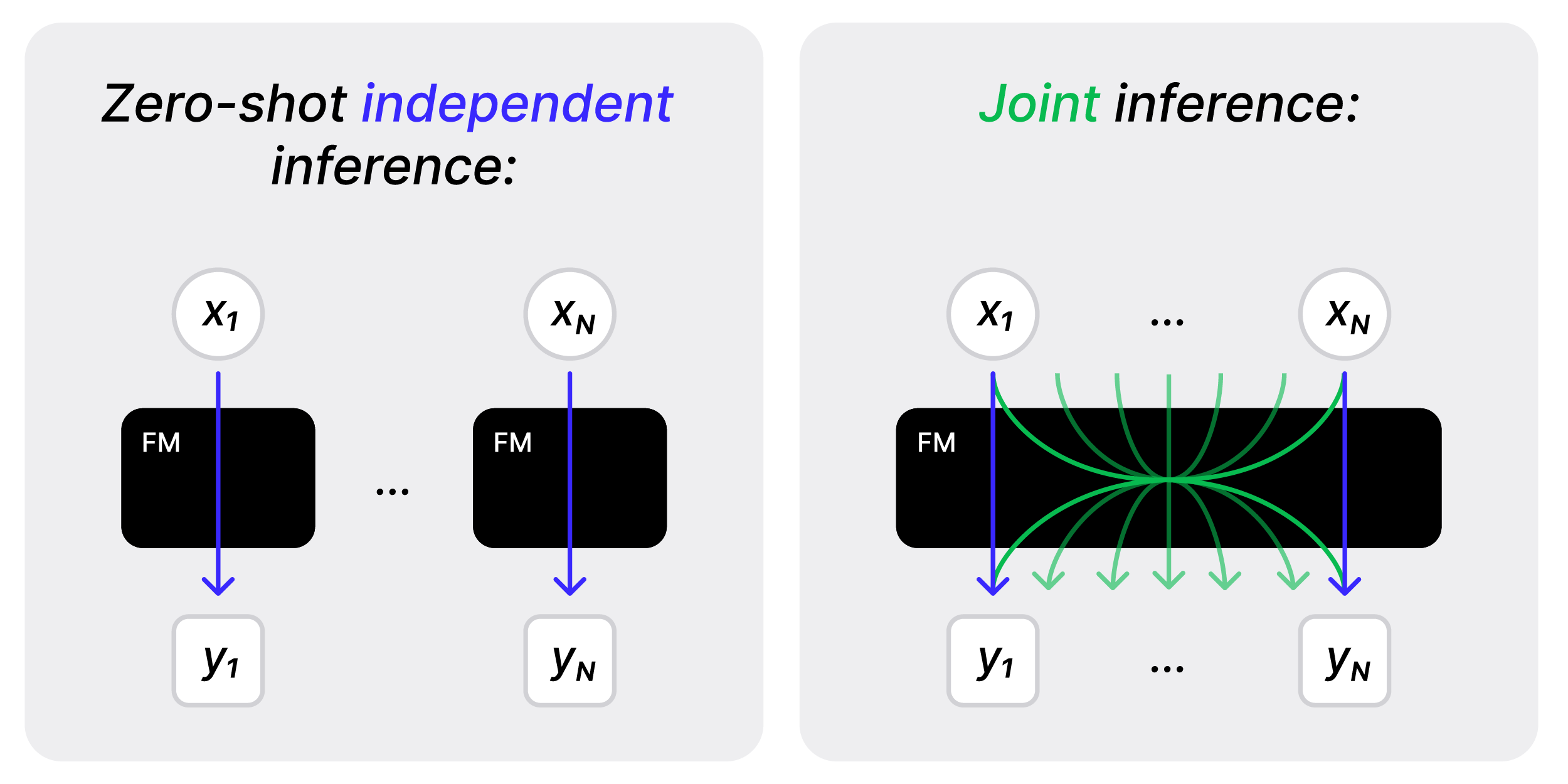
Andrei Atanov*, Artyom Gadetsky*, Yulun Jiang*, Zhitong Gao, Ghazal Hosseini Mighan, Amir Zamir, Maria Brbić ICLR, 2025 [Project Page] [Paper] [GitHub] We introduce a joint inference framework, which makes predictions for multiple inputs simultaneously, leveraging inter-sample dependencies, unlike standard zero-shot inference that makes independent predictions. |

|
Solving Vision Tasks with Simple Photoreceptors Instead of Cameras Andrei Atanov*, Jiawei Fu*, Rishubh Singh*, Isabella Yu, Andrew Spielberg, Amir Zamir ECCV, 2024 [Project Page] [arXiv] [X Thread] How far can a 1-pixel camera go? This project explores solving different vision tasks using a simple photoreceptor (think 1-pixel camera) instead of a high-resolution camera. We find that 1) such simple sensors can solve different vision tasks and 2) their design (e.g., placement) is crucial for their effectiveness. |

|
Andrei Atanov*, Teresa Yeo*, Harold Benoit, Aleksandr Alekseev, Ruchira Ray, Pooya E. Akhoondi, Amir Zamir Arxiv, 2024 [Project Page] [arXiv] [GitHub] We propose a method to generate synthetic training data specifically useful for a given supervised model and image domain. We introduce two feedback mechanisms to guide the generation: 1) model-based and 2) target distribution-based. |

|
for Vision and Robotics Amir Zamir, Andrei Atanov, Andrew Spielberg CVPR Tutorial, 2024 [Web Page] [Recordings] Co-organized a tutorial on computational design. |
|
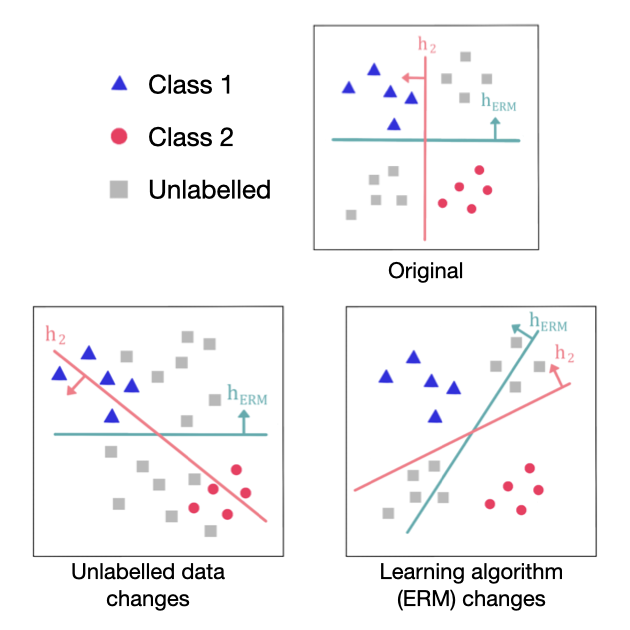
Andrei Atanov*, Harold Benoit*, Liangze Jiang*, Oğuzhan F. Kar, Mattia Rigotti, Amir Zamir ICLR, 2024 [paper] We study the key components of diversification methods that were recently shown to achieve state-of-the-art OOD generalization. We show: 1) they are sensitive to the distribution of unlabeled data, 2) diversification alone is insufficient for OOD generalization and the right learning algorithm is needed and 3) the choice of the learning algorithm and the unlabeled data distribution are co-dependent. |
|
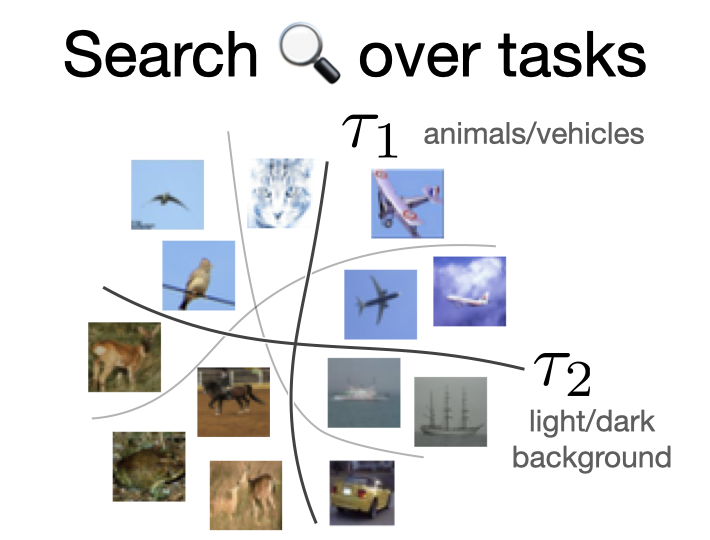
Andrei Atanov, Andrei Filatov, Teresa Yeo, Ajay Sohmshetty, Amir Zamir NeurIPS, 2022 [Project Page] [arXiv] [GitHub] [X Thread] What are the tasks a neural network can generalize on? How do they look, and what do they indicate? We introduce a task discovery framework to approach these questions empirically. These tasks reflect the inductive biases of NNs learned with SGD and can shed more light on how they generalize. Or do not! We show how one can use these tasks to reveal the failure modes of NNs via creating adversarial train-test data partitions. |

|
Roman Bachmann*, David Mizrahi*, Andrei Atanov, Amir Zamir, ECCV, 2022 [Project Page] [arXiv] [GitHub] A new pre-training method that captures and leverages cross-modal interactions. |

|
Oğuzhan Fatih Kar, Teresa Yeo, Andrei Atanov, Amir Zamir, CVPR, 2022 [Oral] [Project Page] [arXiv] [GitHub] 3DCC is a set of more realistic 3D corruptions that can be used as a benchmark or data augmentations. |
|
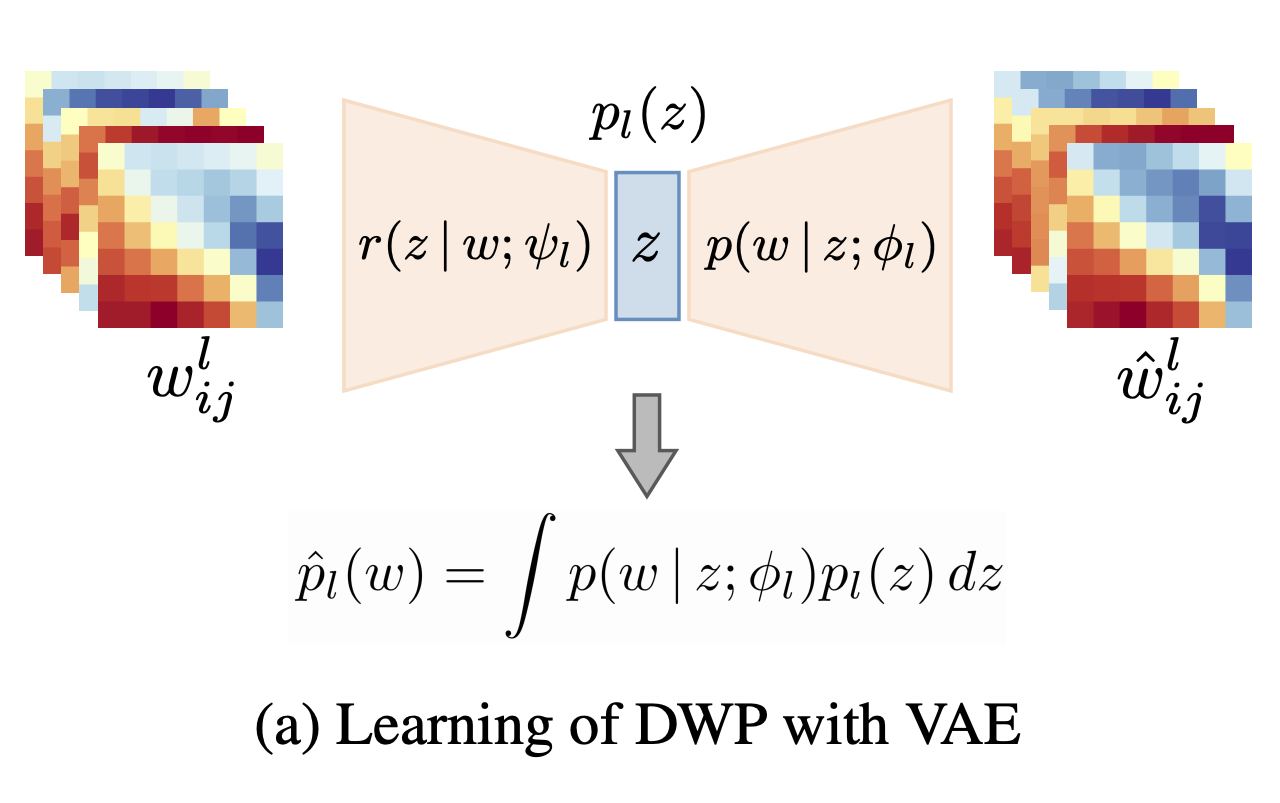
Andrei Atanov*, Arsenii Ashukha*, Kirill Struminsky, Dmitry Vetrov, Max Welling, ICLR, 2019 [GitHub] We propose a flexible prior distribution over convolutional kernels of Bayesian neural networks. |
|
Andrei Atanov, Alexandra Volokhova, Arsenii Ashukha, Ivan Sosnovik, Dmitry Vetrov, INNF Workshop at ICML, 2019 [GitHub] We apply conditional normalizing flows to semi-supervised learning. We utilize multiscale architecture for computational efficiency. |
|
Andrei Atanov, Arsenii Ashukha, Dmitry Molchanov, Kirill Neklyudov, Dmitry Vetrov, ICLR Workshop Track, 2018 We propose a probabilistic view on Batch Normalization and an efficient test-time averaging technique for uncertainty estimation in batch-normalized DNNs. |
|
Credits to Jon Barron for the template. |